We first project the input panning video on to a panoramic canvas (see figure below). We then try to complete this partial space-time volume using a generative video model with outpainting capabilities.
Since the input videos span a wider spatial and temporal range than typical generative video models' context window sizes, we use Temporal Coarse-to-Fine and
Spatial Aggregation strategies to complete the video panoramas.
Temporal Coarse-to-Fine
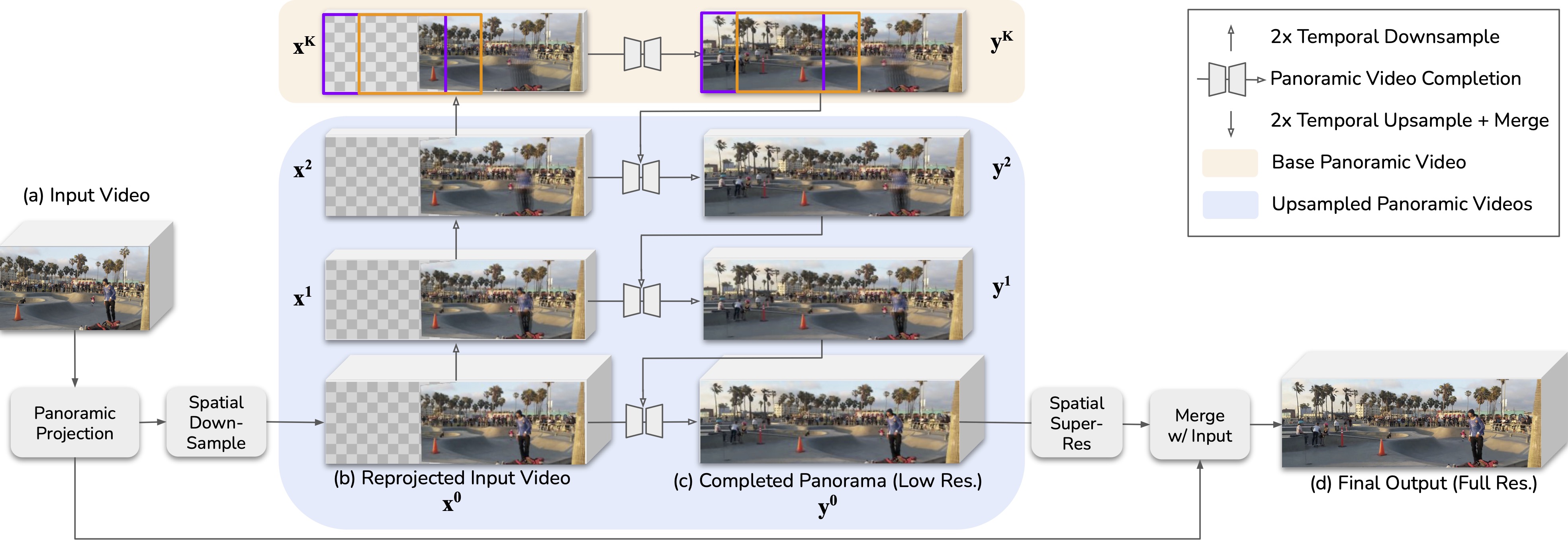
The registered input video (b) is temporally downsampled with temporal prefiltering. A base panoramic video is synthesized at the coarsest temporal scale (top), then gradually
refined by temporal upsampling, merging, and resynthesis (c). Finally, a spatial super-resolution pass is applied and the original input pixels are merged with
the result to produce the output video (d).
Spatial Aggregation
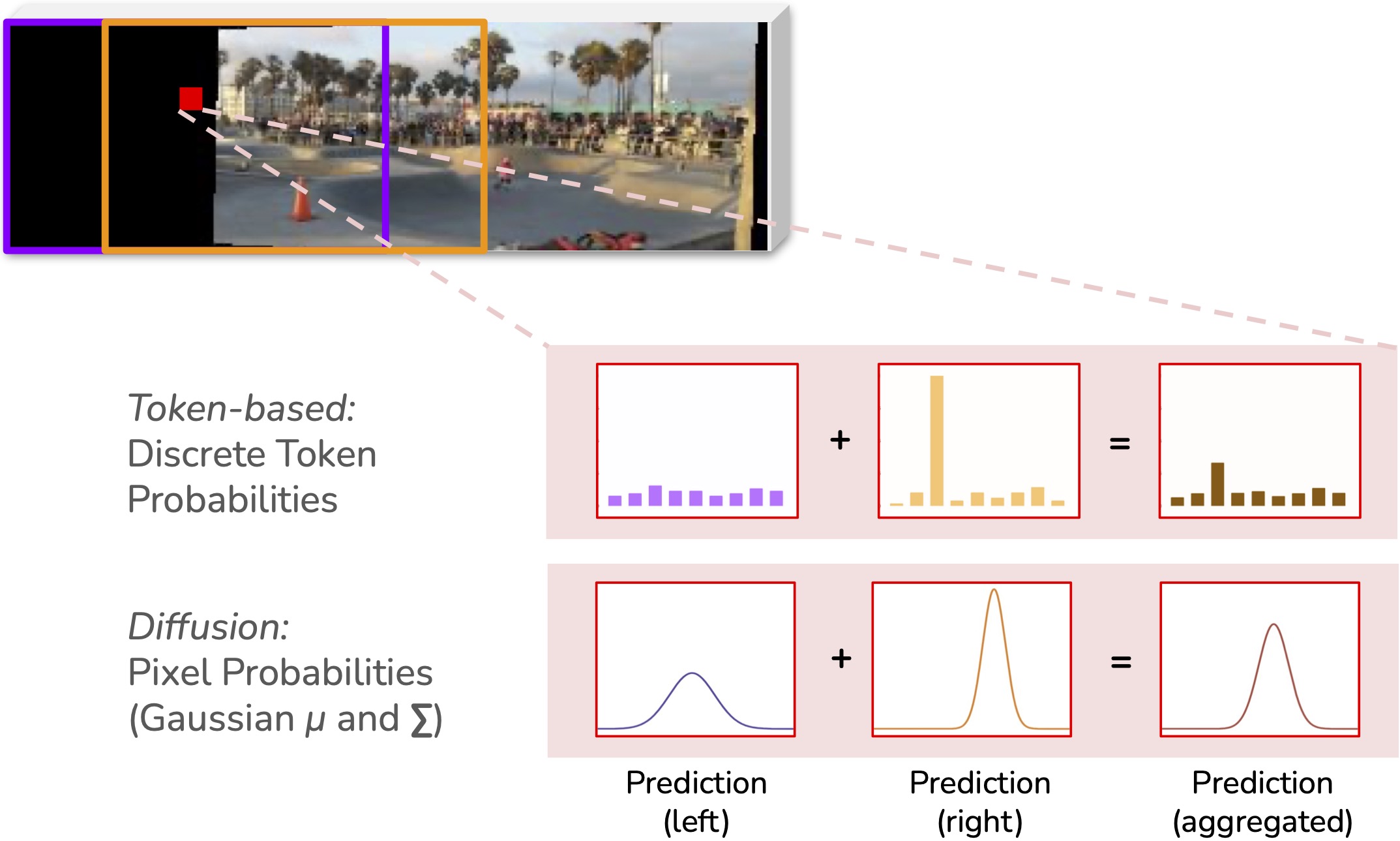
Spatially, we cover the video width using sliding windows and fuse them into one coherent video. To generate a sample in the overlap (red),
we linearly interpolate the two predicted probability distributions (purple, orange) and sample from the aggregated distribution
(brown). With a token-based method the distribution is a discrete distribution over the vocabulary. With diffusion, the distribution is a Gaussian
distribution over pixel values, represented by 𝜇 and Σ.
 VidPanos: Generative Panoramic Videos from Casual Panning Videos
VidPanos: Generative Panoramic Videos from Casual Panning Videos